Subagent Architecture: Delegation, Parallelism & Isolation
When a single agent reviewing 23 files is too slow and too context-heavy, you need subagents. Learn how to dynamically spawn isolated child agents, run them in parallel with thread pools, handle failures gracefully, and aggregate findings — all without context pollution between files.
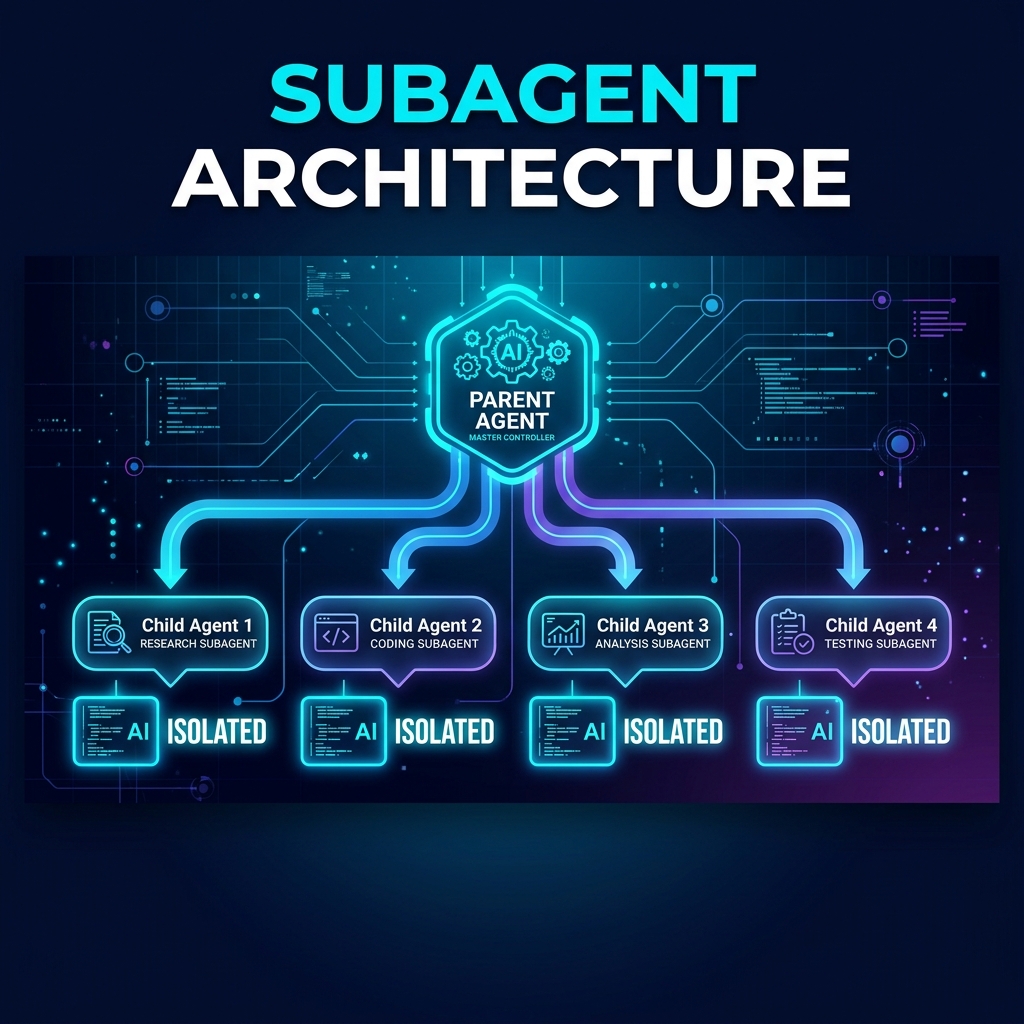
TL;DR: In Parts 1 and 2, we built the DevPulse planner and harness. The harness can execute individual review tasks — but it does so sequentially. In this part, we redesign the execution model: the parent coordinator reads the plan and dynamically spawns isolated child agents for each file, running them in parallel. Each child gets a clean, scoped context with only the information it needs. We handle failures gracefully so a single bad file never blocks the rest of the review.
The Monolith Problem at Scale
Let's be specific about what breaks when you run a single agent across a large PR.
Imagine DevPulse is reviewing PR #847 — 23 modified files. In the sequential approach from Part 2, here is the context window growth across iterations:
Turn 1: [system prompt] + [user message] + [file 1 diff] → ~4,000 tokens
Turn 4: [system prompt] + [history: file 1-2 analysis] + [file 3 diff] → ~11,000 tokens
Turn 10: [system prompt] + [history: file 1-8 analysis] + [file 9 diff] → ~27,000 tokens
Turn 23: [system prompt] + [history: file 1-22 analysis] + [file 23 diff] → ~62,000 tokensBy file 23, the model's context window is full of analysis from the previous 22 files. Three things go wrong:
1. Context Pollution: The model starts cross-referencing findings. A pattern it saw in file 1's auth code gets incorrectly applied when analyzing file 18's UI component. False positives multiply.
2. Attention Drift: With 62,000 tokens of context, the model's attention is spread thin. The original system prompt instructions — "focus only on security issues" — are increasingly ignored as more content competes for attention.
3. Linearity: Files 1 through 23 are reviewed one after another. If each review takes 15 seconds, the total run time is 23 × 15 = ~6 minutes. There is no reason this cannot be 23 parallel reviews taking 15 seconds total.
The solution: a parent-child subagent architecture where each file gets its own isolated agent with a fresh, focused context.
How This Differs from Supervisor Pattern
If you have read Part 6 of our LangChain Core series, you know about the Supervisor pattern — a router agent that directs messages between a fixed set of pre-defined specialist agents.
The difference is important:
| Aspect | Supervisor Pattern | Deep Agent Subagents |
|---|---|---|
| Agent instantiation | Fixed at graph definition time | Spawned dynamically at runtime |
| Number of agents | Predetermined (e.g., 3 specialists) | Variable — could be 2 or 200 |
| Context sharing | Managed through shared graph state | Strictly isolated per child |
| Use case | Routing between different domains | Parallel processing of similar tasks |
| Failure isolation | Failure in one can block graph | Each child fails independently |
The supervisor pattern is ideal when you have distinct expert roles (security agent, performance agent, documentation agent). The deep agent subagent pattern is ideal when you have a dynamic collection of similar tasks (review file 1, review file 2, ... review file N).
In DevPulse, we use both: each file gets a subagent, but within a subagent, we might route to a security specialist or a performance specialist depending on the file type. Part 6 will cover this combination.
The Child Agent Design
A child agent in DevPulse has three defining characteristics:
1. Scoped Context
The child agent receives exactly:
- Its specific task instructions (what type of review, what to look for)
- The diff content for its assigned file
- A minimal tool set (in practice, just
post_review_comment)
It does not receive:
- The PR plan
- Other files' diffs
- Previous children's findings
- The parent agent's reasoning history
2. Structured Output
Rather than returning free-text analysis, child agents return a typed Pydantic object. This gives the parent agent a reliable data contract to work with:
class FileReviewFindings(BaseModel):
file_path: str
review_type: str
issues: List[Issue]
overall_risk: Literal["critical", "high", "medium", "low", "none"]
summary: str
recommended_action: Literal["block", "request_changes", "approve_with_notes", "approve"]
class Issue(BaseModel):
line: Optional[int]
category: str # e.g., "SQL_INJECTION", "HARDCODED_SECRET"
description: str
severity: Literal["critical", "high", "medium", "low"]
suggested_fix: strThe parent aggregator processes these typed objects — not raw strings — making the aggregation logic reliable and testable.
3. Short Lifecycle
Each child agent is created, executes, returns findings, and is garbage collected. It does not maintain state between calls. This is the "share nothing" architecture — each invocation is stateless.
Building the Child Agent
# 04_child_agent.py
import os
from typing import List, Optional, Literal
from pydantic import BaseModel, Field
from langchain_google_genai import ChatGoogleGenerativeAI
from langchain_core.messages import SystemMessage, HumanMessage
from langchain_core.tools import tool
from dotenv import load_dotenv
load_dotenv()
# ---- Structured Output Models ----
class Issue(BaseModel):
"""A single code issue found during review."""
line: Optional[int] = Field(default=None, description="Line number in the diff (if known).")
category: str = Field(description="Issue category, e.g. SQL_INJECTION, N_PLUS_1_QUERY, HARDCODED_SECRET")
description: str = Field(description="Clear, specific description of the issue.")
severity: Literal["critical", "high", "medium", "low"]
suggested_fix: str = Field(description="Concrete, actionable fix recommendation.")
class FileReviewFindings(BaseModel):
"""Complete findings from a child agent reviewing a single file."""
file_path: str
review_type: str
issues: List[Issue] = Field(default_factory=list)
overall_risk: Literal["critical", "high", "medium", "low", "none"] = Field(
description="Highest severity across all found issues, or 'none' if no issues."
)
summary: str = Field(description="2-3 sentence plain-English summary of findings.")
recommended_action: Literal["block", "request_changes", "approve_with_notes", "approve"] = Field(
description="Overall PR action recommendation based on this file's findings."
)
# ---- Review Type Prompts ----
# These are deliberately compact — every token in the system prompt
# is a token NOT available for the actual code diff being reviewed.
REVIEW_PROMPTS = {
"security": """ROLE: Security Code Reviewer
FOCUS: OWASP Top 10 vulnerabilities ONLY.
CHECK FOR:
- SQL/NoSQL injection (raw queries, f-string interpolation in queries)
- Hardcoded secrets, API keys, or passwords
- Insecure authentication (weak hashing like MD5, plain-text comparison)
- Path traversal vulnerabilities
- Broken access control (missing auth checks)
IGNORE: Style, documentation, performance unless it has security implications.
SEVERITY RULES: SQL injection/secrets → critical. Auth bypass → high. Others → medium or low.""",
"performance": """ROLE: Performance Code Reviewer
FOCUS: Performance anti-patterns ONLY.
CHECK FOR:
- N+1 query patterns (queries inside loops)
- Missing database indexes for frequently-filtered columns
- Blocking I/O in async functions (requests.get inside async def)
- Unbounded result sets (SELECT * without LIMIT on large tables)
- Unnecessary repeated computation (same calculation in a loop)
IGNORE: Style, documentation, security issues.
SEVERITY RULES: Blocking I/O in async → high. N+1 queries → medium. Others → low.""",
"test_coverage": """ROLE: Test Coverage Reviewer
FOCUS: Test quality and coverage ONLY.
CHECK FOR:
- New functions/methods added with no corresponding tests
- Tests that only assert True with no real assertions
- Missing edge case tests (null inputs, empty collections, max values)
- Tests that mock so heavily they test nothing real
IGNORE: Style, performance, security.
SEVERITY RULES: Missing tests for auth/payment functions → high. Others → medium or low.""",
"style": """ROLE: Code Style Reviewer
FOCUS: Code quality and maintainability ONLY.
CHECK FOR:
- Missing docstrings on public functions/classes
- Inconsistent naming (mixing snake_case and camelCase in Python)
- Dead code (commented-out blocks, unused imports)
- Functions exceeding 50 lines without clear decomposition
IGNORE: Security, performance, test coverage.
SEVERITY: All style issues are low or medium."""
}
# ---- Child Agent Factory ----
def create_child_agent_llm():
"""
Child agents use a smaller, faster model than the parent coordinator.
Rationale: child agents do focused, single-file analysis.
They don't need the reasoning depth of the parent — they need speed.
Using a cheaper model here keeps the overall cost of reviewing 23 files reasonable.
"""
return ChatGoogleGenerativeAI(
model="gemini-3.5-flash",
temperature=0,
max_retries=2,
request_timeout=45
)
def run_child_agent(file_path: str, diff_content: str, review_type: str) -> FileReviewFindings:
"""
Run a single isolated child agent to review one file.
This is the core unit of DevPulse's parallelism.
Each call to this function is completely independent — it creates its own
LLM instance, its own message history, and returns a typed findings object.
Args:
file_path: The file path being reviewed (used in findings metadata)
diff_content: The git diff/patch content of the file
review_type: One of 'security', 'performance', 'test_coverage', 'style'
Returns:
FileReviewFindings — a typed object the parent aggregator can process
"""
llm = create_child_agent_llm()
# Use structured output to guarantee a typed response
structured_llm = llm.with_structured_output(FileReviewFindings)
system_prompt = REVIEW_PROMPTS.get(review_type, REVIEW_PROMPTS["style"])
# The child agent's entire context — deliberately minimal
messages = [
SystemMessage(content=system_prompt),
HumanMessage(content=(
f"Review the following file diff:\n\n"
f"**File:** `{file_path}`\n"
f"**Review Type:** {review_type}\n\n"
f"```diff\n{diff_content}\n```\n\n"
f"Output a complete FileReviewFindings JSON object."
))
]
print(f" 🔍 [Child Agent] Reviewing: {file_path} ({review_type})")
findings = structured_llm.invoke(messages)
print(f" {'✅' if findings.overall_risk == 'none' else '⚠️'} [Child Agent] Done: {file_path} → {findings.overall_risk.upper()} risk")
return findingsBuilding the Parallel Executor
The parallel executor is responsible for taking the list of tasks from the workspace plan, spawning child agents for each, and collecting results:
# 05_parallel_executor.py
import concurrent.futures
import json
import time
from typing import List, Dict, Optional
from pathlib import Path
from dataclasses import dataclass, field
from 04_child_agent import run_child_agent, FileReviewFindings
from 01_workspace import read_plan, write_finding, update_task_status, read_all_findings
# Mock diff database — in production this comes from the harness's get_file_diff tool
MOCK_DIFFS: Dict[str, str] = {
"src/auth/login.py": """@@ -10,18 +10,24 @@
def login_user(request):
- password_hash = md5(request.POST['password']).hexdigest()
- query = "SELECT * FROM users WHERE username = '%s'" % request.POST['username']
- user = db.execute(query).fetchone()
+ username = request.POST.get('username', '')
+ password = request.POST.get('password', '')
+ query = f"SELECT * FROM users WHERE username = '{username}'"
+ user = db.execute(query).fetchone()
if user:
return create_session(user)""",
"src/auth/tokens.py": """@@ -5,6 +5,8 @@
import jwt
-SECRET_KEY = "hardcoded-secret-123"
+SECRET_KEY = os.environ.get("JWT_SECRET", "hardcoded-secret-123")
+
def create_token(user_id: int) -> str:
- payload = {"user_id": user_id, "exp": time.time() + 3600}
+ payload = {"user_id": user_id, "exp": int(time.time()) + 3600}""",
"src/db/user_repository.py": """@@ -22,6 +22,8 @@
def get_users_with_orders():
+ # Naive implementation — N+1 query pattern
users = db.query("SELECT * FROM users").fetchall()
+ for user in users:
+ user.orders = db.query(f"SELECT * FROM orders WHERE user_id = {user.id}").fetchall()
return users""",
"tests/test_auth.py": """@@ -1,8 +1,14 @@
def test_login():
- assert True # TODO: implement
+ response = client.post("/login", data={"username": "test", "password": "test"})
+ assert response.status_code == 200""",
}
@dataclass
class TaskResult:
"""Result of executing a single review task."""
task_id: str
file_path: str
review_type: str
findings: Optional[FileReviewFindings] = None
error: Optional[str] = None
duration_seconds: float = 0.0
@property
def succeeded(self) -> bool:
return self.findings is not None and self.error is None
def execute_single_task(task: dict) -> TaskResult:
"""
Execute a single review task. Designed to run in a thread pool.
This function is the unit of work for each thread. It:
1. Fetches the file diff (from mock or GitHub API)
2. Runs the child agent
3. Returns a TaskResult (success or failure — never raises)
The never-raises contract is important: if this function raises,
concurrent.futures will swallow the exception and the task silently disappears.
By catching all exceptions and returning TaskResult(error=...), we ensure
every task is accounted for in the final aggregation.
"""
start_time = time.time()
try:
# Fetch diff content
diff_content = MOCK_DIFFS.get(
task["file_path"],
f"# No diff available for {task['file_path']}\n+# Minor update"
)
# Run the child agent
findings = run_child_agent(
file_path=task["file_path"],
diff_content=diff_content,
review_type=task["review_type"]
)
return TaskResult(
task_id=task["id"],
file_path=task["file_path"],
review_type=task["review_type"],
findings=findings,
duration_seconds=time.time() - start_time
)
except Exception as e:
# Catch everything — return a structured failure rather than raising
return TaskResult(
task_id=task["id"],
file_path=task["file_path"],
review_type=task["review_type"],
error=str(e),
duration_seconds=time.time() - start_time
)
def run_parallel_review(workspace_path: str, max_workers: int = 5) -> List[TaskResult]:
"""
Run all pending review tasks in parallel using a thread pool.
Args:
workspace_path: Path to the PR workspace directory (contains plan.json)
max_workers: Maximum concurrent child agents. Default 5.
Why thread pool instead of asyncio?
- LangChain's LLM clients are synchronous by default
- ThreadPoolExecutor gives us true concurrency for I/O-bound work (LLM API calls)
- asyncio would require an async-compatible LLM client throughout
- For 5-20 concurrent files, threads are simple and effective
Why max_workers=5 as default?
- Most Google AI Studio free tier plans allow ~10 req/s
- With 5 concurrent requests, each taking ~3s, we stay within rate limits
- For paid tiers with higher rate limits, increase this to 10-15
Returns:
List of TaskResult objects (one per task, including failed ones)
"""
workspace = Path(workspace_path)
plan = read_plan(workspace)
if not plan:
raise ValueError(f"No plan found in workspace: {workspace_path}")
# Filter to only pending tasks (supports resumability — already-completed tasks are skipped)
pending_tasks = [t for t in plan["tasks"] if t["status"] == "pending"]
pr_number = plan.get("pr_number", "unknown")
print(f"\n🚀 Starting parallel review for PR #{pr_number}")
print(f" Total tasks: {len(plan['tasks'])} | Pending: {len(pending_tasks)} | Workers: {max_workers}")
if not pending_tasks:
print(" ✅ All tasks already completed. Nothing to do.")
return []
results = []
total_start = time.time()
# Update pending tasks to in_progress (for monitoring)
for task in pending_tasks:
update_task_status(workspace, task["id"], "in_progress")
with concurrent.futures.ThreadPoolExecutor(max_workers=max_workers) as executor:
# Submit all tasks to the thread pool
future_to_task = {
executor.submit(execute_single_task, task): task
for task in pending_tasks
}
print(f"\n⚡ {len(future_to_task)} tasks submitted to thread pool...")
# Collect results as they complete (not in submission order)
completed = 0
for future in concurrent.futures.as_completed(future_to_task):
task = future_to_task[future]
result = future.result() # This won't raise — execute_single_task catches everything
completed += 1
progress = f"[{completed}/{len(pending_tasks)}]"
if result.succeeded:
print(f"\n ✅ {progress} Completed: {result.file_path} ({result.duration_seconds:.1f}s)")
print(f" Risk: {result.findings.overall_risk.upper()} | Issues: {len(result.findings.issues)}")
# Write findings to workspace
write_finding(workspace, result.file_path, result.findings.model_dump())
update_task_status(workspace, result.task_id, "completed",
result=result.findings.summary)
else:
print(f"\n ❌ {progress} Failed: {result.file_path}")
print(f" Error: {result.error}")
update_task_status(workspace, result.task_id, "failed", result=result.error)
results.append(result)
total_duration = time.time() - total_start
successful = sum(1 for r in results if r.succeeded)
failed = sum(1 for r in results if not r.succeeded)
print(f"\n📊 Parallel Review Complete")
print(f" Total time: {total_duration:.1f}s (vs {sum(r.duration_seconds for r in results):.1f}s sequential)")
print(f" Succeeded: {successful} | Failed: {failed}")
return resultsUnderstanding the Parallelism Gains
Let's look at the time comparison concretely. With the sequential approach from Part 2:
File 1: 0s ──────────────── 15s
File 2: 15s ──────────────── 30s
File 3: 30s ──────────────── 45s
...
File 23: 330s ──── 345s
Total: 345 seconds (~6 minutes)With the parallel approach using 5 workers:
Worker 1: File 1 (0s-15s) → File 6 (15s-30s) → File 11 (30s-45s) → File 16 (45s-60s) → File 21 (60s-75s)
Worker 2: File 2 (0s-15s) → File 7 (15s-30s) → File 12 (30s-45s) → File 17 (45s-60s) → File 22 (60s-75s)
Worker 3: File 3 (0s-15s) → File 8 (15s-30s) → File 13 (30s-45s) → File 18 (45s-60s) → File 23 (60s-75s)
Worker 4: File 4 (0s-15s) → File 9 (15s-30s) → File 14 (30s-45s) → File 19 (45s-60s)
Worker 5: File 5 (0s-15s) → File 10 (15s-30s) → File 15 (30s-45s) → File 20 (45s-60s)
Total: ~75 seconds (~1.25 minutes) — 4.6x fasterThe actual speedup depends on your max_workers setting relative to your API rate limits. With a higher-tier API plan, you could run 15-20 concurrent workers and review 23 files in under 30 seconds.
Aggregating Findings
The parent coordinator reads all findings from the workspace and produces a consolidated review:
# 05_parallel_executor.py (continued)
class ConsolidatedReview(BaseModel):
"""The final aggregated review report for the entire PR."""
pr_number: int
total_files_reviewed: int
total_issues: int
critical_issues: int
high_issues: int
pr_recommendation: Literal["block", "request_changes", "approve_with_notes", "approve"]
files_by_risk: Dict[str, List[str]] # {"critical": [...], "high": [...], ...}
markdown_report: str
def aggregate_findings(workspace_path: str, pr_number: int) -> ConsolidatedReview:
"""
Read all subagent findings from the workspace and produce a consolidated report.
Aggregation logic:
- PR recommendation is the worst finding across all files
- Issues are counted and grouped by severity
- Markdown report is formatted for GitHub PR comments
"""
workspace = Path(workspace_path)
all_findings = read_all_findings(workspace)
if not all_findings:
return ConsolidatedReview(
pr_number=pr_number,
total_files_reviewed=0,
total_issues=0,
critical_issues=0,
high_issues=0,
pr_recommendation="approve",
files_by_risk={"critical": [], "high": [], "medium": [], "low": [], "none": []},
markdown_report="No files were reviewed."
)
# Aggregate metrics
total_issues = 0
critical_issues = 0
high_issues = 0
files_by_risk: Dict[str, List[str]] = {
"critical": [], "high": [], "medium": [], "low": [], "none": []
}
# Build markdown report sections
report_lines = [
f"# 🤖 DevPulse Automated Code Review\n",
f"**PR #{pr_number}** | **Files Reviewed:** {len(all_findings)}\n",
"---\n"
]
# Determine overall recommendation (most severe wins)
recommendation_priority = ["block", "request_changes", "approve_with_notes", "approve"]
overall_recommendation = "approve"
for finding_data in sorted(all_findings, key=lambda x: x.get("overall_risk", "none")):
# Parse the stored finding
file_path = finding_data.get("source_file", "unknown")
overall_risk = finding_data.get("overall_risk", "none")
issues = finding_data.get("issues", [])
summary = finding_data.get("summary", "No summary available.")
recommended_action = finding_data.get("recommended_action", "approve")
# Update metrics
total_issues += len(issues)
for issue in issues:
if issue.get("severity") == "critical":
critical_issues += 1
elif issue.get("severity") == "high":
high_issues += 1
files_by_risk.setdefault(overall_risk, []).append(file_path)
# Update overall recommendation (take the worst one)
if (recommendation_priority.index(recommended_action) <
recommendation_priority.index(overall_recommendation)):
overall_recommendation = recommended_action
# Add to report
risk_emoji = {
"critical": "🔴 CRITICAL",
"high": "🟠 HIGH",
"medium": "🟡 MEDIUM",
"low": "🟢 LOW",
"none": "✅ CLEAN"
}.get(overall_risk, "⚪ UNKNOWN")
report_lines.append(f"### `{file_path}` — {risk_emoji}\n")
report_lines.append(f"{summary}\n")
if issues:
report_lines.append("**Issues Found:**\n")
for issue in issues:
sev_badge = {"critical": "🔴", "high": "🟠", "medium": "🟡", "low": "🟢"}.get(
issue.get("severity", "low"), "⚪"
)
line_ref = f" (line {issue['line']})" if issue.get("line") else ""
report_lines.append(
f"- {sev_badge} **{issue.get('category', 'ISSUE')}**{line_ref}: "
f"{issue.get('description', '')}\n"
f" *Fix: {issue.get('suggested_fix', 'N/A')}*\n"
)
report_lines.append("\n---\n")
# Summary footer
recommendation_display = {
"block": "🛑 BLOCK — Do not merge. Critical issues must be resolved first.",
"request_changes": "⚠️ REQUEST CHANGES — Non-blocking issues require attention.",
"approve_with_notes": "📝 APPROVE WITH NOTES — Minor issues, but safe to merge.",
"approve": "✅ APPROVED — No significant issues found."
}.get(overall_recommendation, "⚪ UNKNOWN")
report_lines.insert(2, f"**Overall Recommendation:** {recommendation_display}\n")
report_lines.insert(3,
f"**Issues:** {total_issues} total | {critical_issues} critical | {high_issues} high\n\n"
)
# Write the final report to workspace
report_path = Path(workspace_path) / "final_review.md"
with open(report_path, "w") as f:
f.write("".join(report_lines))
print(f"\n📋 Final report written to {report_path}")
return ConsolidatedReview(
pr_number=pr_number,
total_files_reviewed=len(all_findings),
total_issues=total_issues,
critical_issues=critical_issues,
high_issues=high_issues,
pr_recommendation=overall_recommendation,
files_by_risk=files_by_risk,
markdown_report="".join(report_lines)
)
if __name__ == "__main__":
from 01_planner import run_planning_phase
# Step 1: Generate plan (from Part 1)
sample_files = [
"src/auth/login.py",
"src/auth/tokens.py",
"src/db/user_repository.py",
"tests/test_auth.py"
]
plan = run_planning_phase(
pr_number=847,
pr_title="Refactor authentication system with JWT token rotation",
modified_files=sample_files
)
# Step 2: Run parallel review (this part)
results = run_parallel_review(
workspace_path=plan["workspace_path"],
max_workers=3 # Conservative for API rate limits
)
# Step 3: Aggregate findings
consolidated = aggregate_findings(plan["workspace_path"], pr_number=847)
print(f"\n{'='*60}")
print(f"PR #{consolidated.pr_number} Review Complete")
print(f"{'='*60}")
print(f"Files Reviewed: {consolidated.total_files_reviewed}")
print(f"Total Issues: {consolidated.total_issues}")
print(f"Critical: {consolidated.critical_issues} | High: {consolidated.high_issues}")
print(f"Recommendation: {consolidated.pr_recommendation.upper()}")
print(f"\nMarkdown Report Preview:")
print(consolidated.markdown_report[:1000])Graceful Failure: Why Never-Raise Matters
The execute_single_task function is written to never raise. Let's think about why this matters:
# What happens if execute_single_task raises?
future_to_task = {
executor.submit(execute_single_task, task): task
for task in pending_tasks
}
for future in concurrent.futures.as_completed(future_to_task):
result = future.result() # If execute_single_task raised, THIS raises
# Everything below this line is skipped for the failed task
write_finding(...) # Never executed
update_task_status(...) # Never executed — task stays "in_progress" in planIf future.result() raises, the exception propagates into the for loop. Depending on how you handle it:
- If you catch it: you know the task failed, but you only know the exception message — not which file, which review type, or what the agent was doing
- If you don't catch it: the entire
run_parallel_reviewfunction crashes, and all other completed tasks' results that haven't been processed yet are lost
By wrapping everything inside execute_single_task and returning a TaskResult with either findings or error, we guarantee:
- Every task produces exactly one result object
- The task failure is recorded in the workspace (
update_task_status(... "failed")) - The parent continues processing all other successful tasks
- The failed task can be retried on the next run (because its status is
"failed", not"completed")
This is the isolation in subagent isolation — not just context isolation, but failure isolation.
FAQs
Q: How do you decide max_workers? Is there a formula?
A: Start with: max_workers = min(API_rate_limit_per_second × avg_latency_seconds, max_files_per_PR). For example, if your API allows 10 requests/second and each LLM call takes 3 seconds on average, you can sustain about 30 concurrent requests — but that is almost certainly higher than your rate limit burst quota. In practice: start at 5, monitor your rate limit errors in the logs, and increase gradually. Never set it above your paid tier's burst limit.
Q: What happens if a child agent's structured output fails to parse (the LLM returns invalid JSON)?
A: with_structured_output() in LangChain handles this at the binding level — if the model returns a malformed response, it retries internally up to max_retries times. If all retries fail, it raises a langchain_core.exceptions.OutputParserException. Our execute_single_task catches this and returns a TaskResult with error=str(e). The task is marked as "failed" in the workspace plan.
Q: Why not use asyncio instead of threads?
A: This is a reasonable choice for async-native code. The reason we use threads here: ChatGoogleGenerativeAI and most LangChain LLM clients are synchronous. Running them in asyncio would require either wrapping them in asyncio.to_thread() (which is essentially threads anyway) or using the async variants of every LangChain primitive. Threading gives us equivalent concurrency for I/O-bound tasks (which LLM API calls are) with simpler code. If your codebase is already fully async, the async variant is equally valid.
Q: Can the parent agent inspect child agents' intermediate reasoning, not just their final output?
A: Not with this architecture — by design. Child agents return a single typed output, and the parent only sees that output. This is the tradeoff of context isolation. If you need intermediate reasoning visibility, you would use LangSmith tracing (Part 5), which captures the full chain of events inside each child agent without exposing it to the parent's context window.
Continue to Part 4: Context Engineering — Write, Select, Compress, Isolate →